2023年11月17日上午,我校考古文博学院研究生课程《考古学研究》研究生必修课程讲座第五讲《大数据时代的考古学:从考古统计学到考古数据科学》在考古文博学院A座101举行,由我校考古文博学院宋殷助理教授主讲。

宋殷助理教授主讲

讲座现场
一、引言
讲座伊始,宋殷老师介绍了本次讲座讨论的两个重点。一是“大数据时代“,即数据大量、更新快、多样化的时代,并提出了“考古学是否已经进入了大数据时代”的问题。而第二个主要讨论的问题是“预测”。《史记·周本纪》、《论语》等书中都有记载历史上著名的预测,而考古学中是否也可以通过已有的研究去预测其他考古发现的情况呢?随后介绍了科林·伦福儒书中写到的贸易模式案例。古人的贸易模式包括直接贸易、线下贸易、中间人贸易等,多达十种,但根据其复原出的线下贸易和中心地再分配的模型仅有两种。伊恩·霍德也发现了相似的状况,多种贸易模式的数量随距离变化的曲线都是很接近的。多种可能性都会在考古学中呈现出相似的物质特征,单单使用简单的统计学,很难对此进行进一步区分。如何通过数据深入剖析这类问题的成因,是接下来将要讨论的问题。随后从统计学与数据科学二者的发展史角度切入,从历史上英国征服者威廉对全国的人口统计到过去四个世纪中发展出的概率论、高斯分布、卡方分布等理论成果。而20世纪John W. Tukey发表的《The Future of Data Analysis》则将统计学引入了数据科学的时代。他提出最重要的概念就是探索性数据分析(Exploratory Data Analysis),即对已有数据在尽可能少的先验假设下,通过作图、制表、方程拟合、计算特征量等手段,探索数据的结构和规律的一种数据分析方法。传统统计学倾向于先假设数据符合某一种统计模型,然后依据数据样本来估计模型的一些参数及统计量,以此来了解数据的特征,因此常因为实际数据不符合假设的统计模型分布,而导致数据分析结果不理想。而探索性数据分析认为数据具有未知的分布情况,需要先探索这个数据的分布,再进行进一步的分析。它强调“让数据说话”,通过探索性数据分析,我们可以最真实直接的观察到数据的结构和特征。而数据分析的过程分为探索阶段和验证阶段两步,探索阶段侧重于发现数据中包含的模式及模型,而验证阶段则侧重于评估模型。关于如何进行探索性数据分析以及建模,这部分为本次讲座的重点。
二、数据科学:探索性数据分析
数据科学是从数据中提取知识和见识的一门科学。其分析流程可以概括为:大量的数据中,有其相应背景的信息附着于这些数据上,通过这些背景的信息和数据本身,可以建立数据间的联系网络,可以被理解为“知识”。随后就可以在某点到另一点之间建立出联通的渠道,并对未知的数据进行预测。后两步即为利用模型进行预测的研究过程。如图1所示的是从数据库中获取知识的步骤。首先从大量的数据中选择部分对所研究问题有帮助的目标数据,然后进行一些预处理和数据的转换,并进行可视化等操作,对数据建模,通过这种模式再对数据进行进一步的解释和评估,得到知识层面的信息。
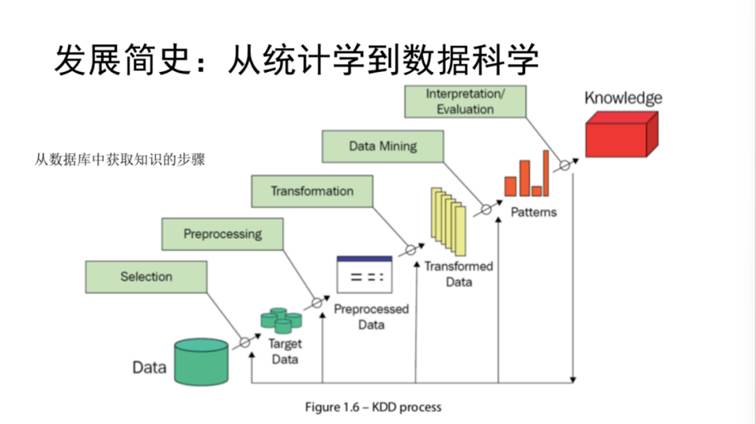
图1
传统统计学的过程是从总体的数据中通过概率的方式抽取部分为样本,然后对样本进行描述统计,得到样本分布情况,再通过其回推,完成推断统计的过程。宋老师认为统计学有三种境界,第一种是描述,第二种是推断,第三种是预测。描述统计包括均值、中位数、4分位差、4分位数极差等。在描述统计的基础上,作进一步的推断统计,需要运用到正态分布,t分布、卡方分布等,对数据与真值的距离进行推断。这个过程会认为数据是来自于某个正态分布的总体,并对该总体进行平均值和标准差的推断过程。而第三步是预测的过程,即通过回归分析对数据进行动态推断,即通过数据之间的关系建立回归方程,并对未知的数据进行一个预测。描述统计是基础,是对数据的描述与观察,而推断统计是借助某些分布函数对未知真值进行静态推断的一个过程。回归分析则属于预测,是动态的推断过程,随着自变量的变化,而对因变量不断进行推断。需要注意的是,推断统计需要借助于已有的分布函数来进行,是有限信息的分析过程。而与之相比,探索性数据分析的理念就是抛开先验信息不管,先从数据本身去看其分布规律。该分析方法主要依托于包括茎叶图、镶嵌图以及直方图和核密度图。随后宋老师重点介绍了核密度图(图2),其来源于直方图,图中红色虚线表示正态分布曲线,代表左图的每个点,把它加起来就能得到蓝色曲线,而正态分布曲线具有平均值(每一个点的具体的值)和标准差(公式中的带宽h)。当h取不同值的时候,得到的这个核密度曲线也是不同的。右图中灰色线为数据原始的分布曲线,而按照正态分布曲线取100个点得到蓝色的线段,可根据h的不同取值得到绿、红以及黑色曲线。其中,黑色曲线和灰色曲线最为相符,由此可知h取值过大或者过小的时候,都会使之偏离原始分布。
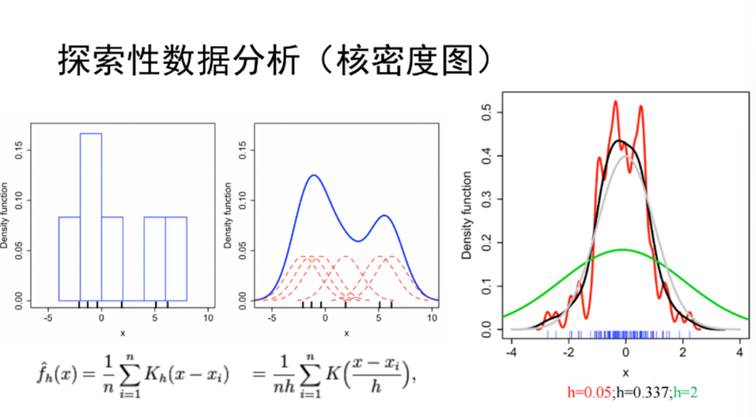
图2
举例来说,《黄陵寨头河与史家河墓地人骨稳定同位素研究》一文中,作者对碳氮同位素进行分析,基于正态分布的样本,进行平均值标准差计算,得到结果认为两个墓地之间不存在显著性差异,两个人群食谱结构相似。而通过核密度曲线制作二维合并的图(见图3),红色区域密度高,绿色区域密度低。可以看到,左图的遗址有两个数据集中分布的区域,而右图仅有一个,因此比较可以看出两个墓地人群食性有一定差别的,从而得出与作者不同的结论。
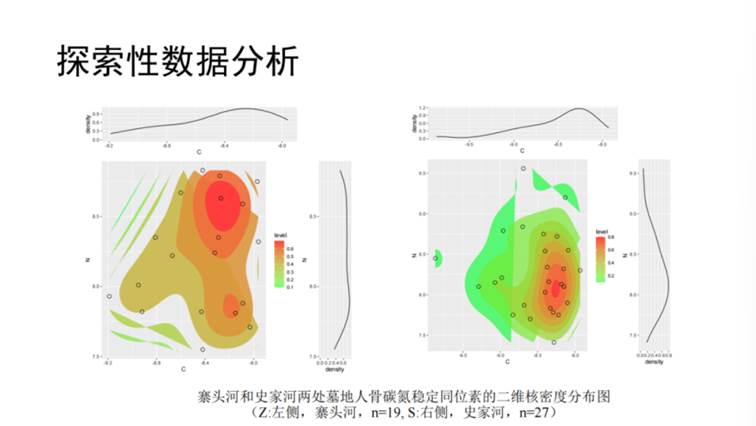
图3
宋老师分享了自己的研究,关于西周春秋时期三晋两周地区的椁室制度研究。棺椁重数确定墓主人身份地位非常关键的信息,但是大墓往往反复遭到盗掘,很难复原棺的数量。但是椁室面积依然是可以被复原的,并作为参考。通过探索性数据分析建立椁室面积与等级之间的关系,可以进一步预测根据椁室面积预测墓葬等级。
三、机器学习
机器学习与计算机程序员具有迥异的逻辑。面对一批新数据,计算机程序员会使用已有算法将其拟合并得到答案(ground truth)。而机器学习则根据一批数据以及这批数据的答案,摸索其中的算法,并根据更多的数据进行预测。机器学习背后的核心观念,即学习可以被看作是通过使用可靠的模型来解释观测数据的过程,而机器可以用这样的模型来预测未来的数据,并给出理性的决策。讲座开始时提到的预测的问题,就可以通过机器学习的方式实现。首先介绍几种简单的机器学习算法。首先是k最近邻算法(k-nearest neighbor),即某个点周围的k个点中最多数的点的性质决定了该点的性质,可用于预测该点的性质,即“物以类聚”。其关键为确定参数k的取值,如图4判断未知点(标为绿色)属于红色还是蓝色,当k=3时, 2/3是红色,未知点很有可能是红色。但如果k=5时 3/5是蓝色,则未知点更有可能是蓝色,因此不同的k值下对点的预测情况是不一致的。此外,还需要计算未知点与周边其他点的距离(一般为欧氏距离),并对特征归一化。一般情况下,参数k不能取值太小,会导致过拟合,而取值过大会导致平均化,这两种情况都会使得预算能力变差。k介于某个中间值时,会获得最好的拟合效果。这类算法用于考古学文化分布中,可以预测未知遗址点的考古学归属。
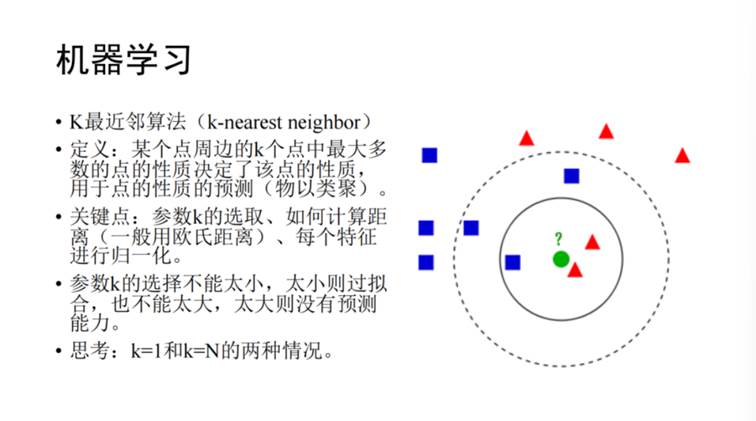
图4
机器学习方法有许多种,监督学习(Supervised Machine Learning)可找到将输入数据与输出信号进行对应的算法,并用该算法进行预测。数值型变量通常使用回归分析,而对于分类变量一般是决策树分析,其中决策树分析是一个较为清晰明确的分析方法,会把每一步过程展示清楚。非监督学习(Un-supervised Machine Learning)是只有输入数据而没有输出信号的学习,一般为聚类分析。此外还有贝叶斯统计等。
1、监督学习
线性回归(Linear Regression, LR)即认为自变量X和因变量(预测变量)Y之间存在线性关系(Y=a*X+b),其中自变量X为可以控制或获得的变量,因变量Y为需要进行预测的变量,其线性关系就是用自变量去预测因变量的模型。皮尔逊相关系数R为量度符合线性成都的系数,R2越接近1,线性越好,线性预测模型的预测能力越强。此外需要注意,具有相关性不等于具有因果关系。New England Journal of Medicine在2012年曾经刊登过一篇文章,讨论巧克力消费能力与诺贝尔奖得主的相关性。作者发现不同国家的人均巧克力消费量及人均诺贝尔奖获得次数具有极清晰的相关性,因此认为食用巧克力对于智商有正面影响。宋老师认为该结论并不正确,因为巧克力消费量高说明国家经济实力强,国民受高等教育率较高,因此导致诺贝尔奖得主的人数多。巧克力消费量和诺贝尔奖得主人数之间并没有简单的对应关系,不可以将因果关系与相关性简单混淆。该方法应用于考古学问题中需要谨慎。在余静老师2011年发表的《多元统计分析方法在汉墓等级划分中的应用--以安徽南部西汉早期墓为例》一文中,进行了墓葬规模(墓室面积)与陶鼎数量的线性回归计算,而陶鼎数量时整数型的分布,并不是连续的数值变量。另外,如图5所示,每一种陶鼎数量可以对应多种墓葬规模,该种数据制作回归模型缺乏预测能力。对此进行正态性检验,计算回归残差时p<<0.05,说明数据并未通过正态性检验,并不能使用线性回归方法对该问题进行研究,会导致研究结果出现谬误。
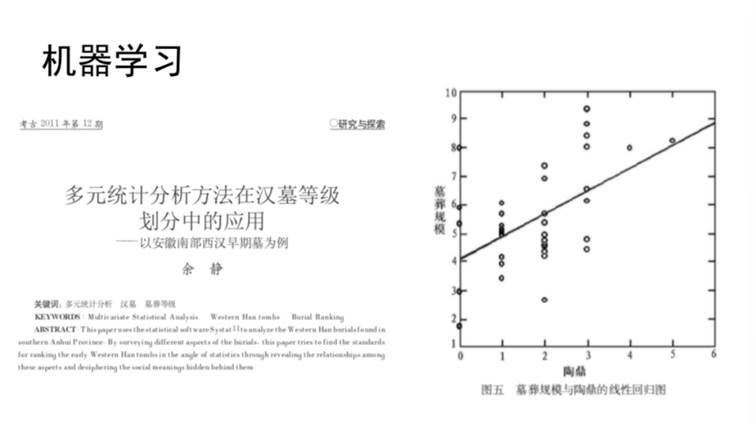
图5
宋老师讲解了自己使用监督学习针对数值型变量进行回归分析,研究夏商周时期世系与积年。通过春秋时期各诸侯国国君的世系和积年关系建立机器学习函数,可用来预测夏、商、西周时期的情况,得到了非常清晰明确的年表,并与古本《竹书纪年》的夏商西周纪年记载相吻合。另一类方法是使用决策树(Decision Tree)对分类变量进行分析。以电子邮箱中区分垃圾邮件的分类系统为例,根据可疑词汇、未知发件人等信息进行逐步分类,并筛选垃圾邮件。随着决策树分析中分支的增加,每个分支下的样本量会减少,因此需要保证每个分支下样本数量足够多,否则分类过程会遭到噪音的干扰。这个过程与器物类型学相似,邹衡先生《论古代器物的型式分类》中对器物类型的分类方法与针对分类变量的进行决策树分析的过程具有相似的内核。山东大学路国权老师《南北二系:试论东周时期铜匜的分类和谱系》一文中首先根据腹部的长径的纵横方向分型,然后根据流、足、鋬逐步细分。其中,第一步的分类时决定了分类系统性质的最关键步骤。该研究的分类结果根据横长和纵长两类被分为周和楚两个系统,即南北二系,而其余分类对系统整体影响较小。崔剑锋老师在课上曾举过根据元素含量判断未知瓷片所属窑口的案例。首先测试临汝窑、龙泉窑、越窑的瓷片成分,使用如图6代码,首先分类三窑含量差异最大的Sr元素,随后进一步分类,可以得到一个分类算法,并用于判断未知瓷片所属窑口。

图6
决策树方法可以用于分类复杂的数据集。在研究泰坦尼克号幸存者的分类时,每个人都有所属舱位、性别、年龄、存活情况的背景信息数据。首先按照性别分类,然后按照舱位、年龄分类,可从结果上看出未成年人和妇女的存活率较高,说明在危险情况下谦让妇女儿童是当时的普遍现象。可以使用rpart.plot()函数作图(如图7),给出每个类别所占百分比,并用类似的方法让类型学研究更加科学化。需要注意的是,样本需要有标签才能建立模型,在泰坦尼克号的例子中即为“是否存活”,且叶子的样本量必须足够多,才能使分类具有一定功能。《罗越与中国青铜器研究》一书中作者贝格利对比了罗越与高本汉对青铜器分类方法和逻辑的区别。高本汉的分类是自上而下的逻辑分类,是由数据和算法得到答案的过程,更接近于“程序员”;而罗越的分析方法是自下而上的逻辑分类,由数据和答案推导算法的过程,更接近于机器学习。在选择算法时,应充分考虑材料和数据的特性,应具有目的性而非盲目的选择。
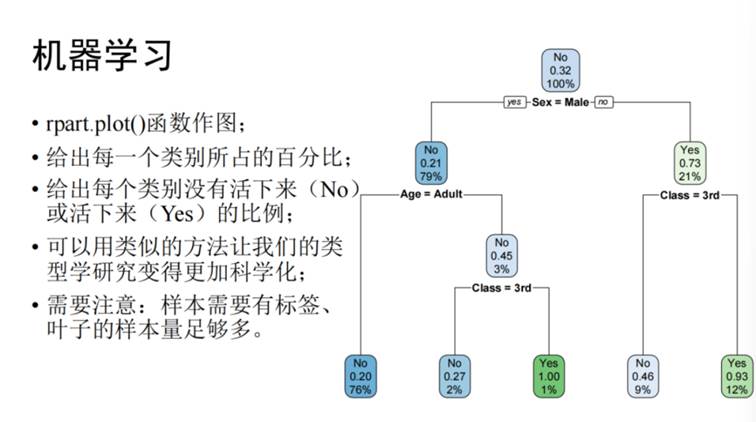
图7
2、非监督学习
k-均值聚类(k-means),即首先指定随机数k,选择k个样本作为初始的聚类中心,然后计算每个样本与中心的距离d,并将样本归类于d最小的聚类中,并重新计算该聚类的中心值,并计算每个样本与其距离,重新分类,重复该过程直到收敛,计算过程如图8所示。王含元老师的《大甸子墓地社会结构的再探讨——基于K-均值聚类方法 》基于该方法,分析了墓葬面积、壁龛、木质葬具数量、二里头文化风格陶容器等10多个指标进行k均值聚类分析,得到了5个聚类结果,因此得出社会分为五个阶层。
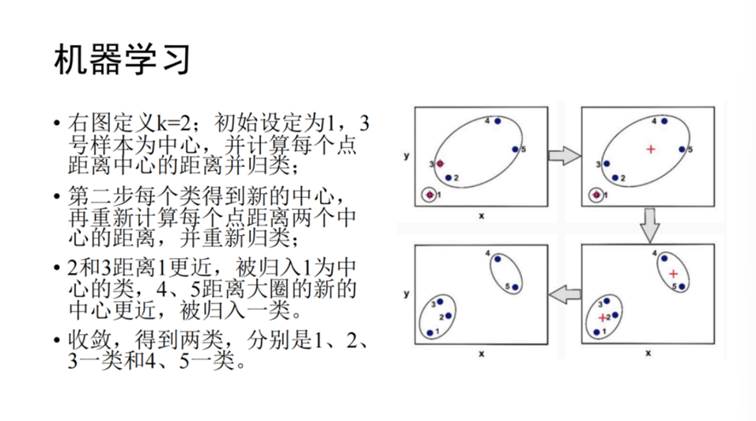
图8
宋老师认为,选择划分墓葬等级的标准并不是绝对的,因为不同因素所占的权重不同。对于非监督学习,数据没有“标签”,因此墓葬的真实等级是无法得知的,因此无法建立学习模型,只能通过聚类的方法看其情况,而并不能解决墓葬等级的问题。然而聚类本身的等级划分标准是今人认为选定的,并非是古人眼中的标准,因此会存在主位分类和客位分类的问题。雷兴山老师也多次强调该问题。决定聚类结果是否可靠的因素在于数据的质量,当能确保每个样本的标签,就可以建立数据的机器学习模型,否则无法探讨相关问题。
3、贝叶斯统计
贝叶斯统计是通过数据和相关的信息对客观世界进行认识(先验条件),然后根据获得的数据和相关信息,去改变经验认识,并得到后验认识,用这类方法不断进行认识迭代的过程。举例来说,假设有一场认陶器的考试,参与者分别为考古系本科生和无基础的考古小白,我们需要通过某学生是否认出陶器的情况来猜测该学生有多大概率是考古系学生。假设不知道某生为考古学生还是考古小白,先验概率为50%。而考古系学生中,90%人可以认出陶器,则认出陶器的概率是0.45;10%的考古系学生不能,认不出概率是0.05。而考古小白仅有20%的概率能认出陶器,则认对的概率为0.1,认错的为0.4。如图9可以根据公式计算出,该生如果认对了陶器,他是考古系概率的学生为0.45/(0.45+0.1)=0.81。贝叶斯统计可以概括为a事件和b事件交叉的区域的面积除以b事件的面积,可得到了b事件发生的情况下a事件的发生概率。
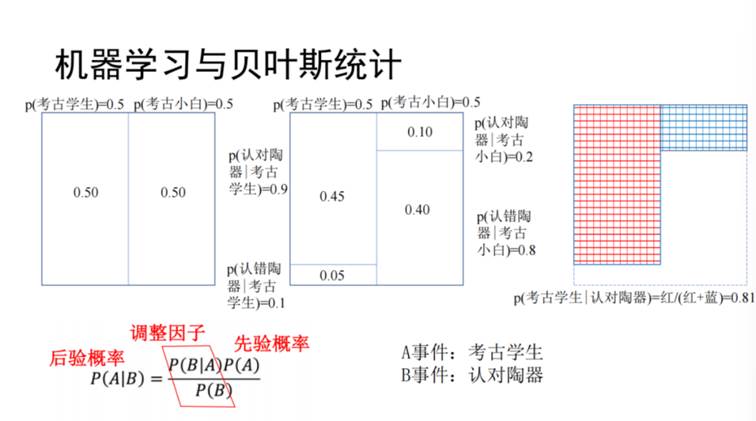
图9
《吕氏春秋》中也有“疑邻窃斧“的故事:人有亡斧者,意其邻之子,视其行步,窃斧也;颜色,窃斧也;言语,窃斧也;动作态度无为而不窃斧也。俄而抇于谷而得其斧,他日复见其邻人之子,动作态度无似窃斧者。在这个故事中,先验概率是这个人认为邻居家的儿子偷了斧子,但是他在找到自己的斧头后,即获得了新的观察数据后,就不觉得邻居的儿子像偷斧子的人了,也就是说先验认识会影响人们的判断,但是观察数据可以颠覆这个判断。
四、结语:考古学是否进入了大数据时代
在讲座末尾,宋老师带大家回到讲座开始是提出的问题:考古学是否进入了大数据时代?宋老师认为,大数据时代并非单纯的数据量增大。数据分级的情况十分重要,优质的数据具有较为全面的背景信息。而考古中最普遍存在的则是背景信息缺失的数据。因此,在考古的数据分析中,尤其需要注意的是数据量反映的是优质数据还是非优质数据,从而使用不同的预处理方法对待。我们应该用优质的数据建立模型。此外,还需要注意数据转换的问题。并非所有收集到的数据都能进行建模,需要对数据进行适当转换,如log转换、倒数转换、或将数据整合为一个参数(如BMI)。 “幸存者偏差“也是一个常见问题,我们在考古学中搜集到的数据通常很难不能完整的反应真实的情况,需要评估观测时出现的问题。比如研究石器时,通常更多找到中小型的石器,这可能是因为较大的石器容易破损;研究墓葬时,由于大墓容易被盗,完整大墓的占比会降低。”冰山效应“则是指隐藏数据和已发表数据之间存在的关系。大量的考古数据没有产生的时候就已经遭到了破坏,或由于技术限制而没有获得相关信息,也可能获得了数据尚未发表。而面对已发表的数据,需要注意标准是否一致,是否有充分的背景信息做支持,是否是一批完整的数据。真正的大数据研究是对数据整体进行研究,与统计学上对整体的一部分进行抽样研究不同,这也是二者的本质性区别。最后,宋老师就如何走向考古数据科学的问题进行了总结和展望。数据科学的基本研究流程是搜集数据、整理清洗和转换数据、探索性数据分析、数据可视化、建模、评估模型与进行预测。在考古学中有一部分数据是不可以被预测的,需要注意研究尺度的变化。比如遗址预测模型,或者通过陶片预测陶器整体的形状、通过陶器形状预测年代都是可行的。在过程主义考古学中,运用民族学和实验考古等中程理论也可以进行建模预测。但是,在考古信息匮乏的时候无法进行预测,因为有很多可能的成因会导致产生相似的考古现象,这时就要参考后过程主义考古学的思路。考古学中强调“由已知推导未知”,“古今一体”,但是哪些内容是可以推导的,哪些是不能推导的,这也是需要在研究中深思的内容。机器学习、建模、决策树、聚类,各种手段的目的是一样的:找出考古现象背后因果关系的这条红线,是考古学家的使命和不懈努力的目标!

图10
本文已经宋殷老师审核
撰稿:姚睿彤
 信息资料
信息资料



.jpg)